
The main target groups of machine translation have always been companies because they need translation resources more urgently than personal users at home. That's why, even today, the fact that most effective translation systems are very expensive and only affordable for companies and not for single users is obvious. It always takes a few years’ time until a software gets cheaper, because then new developments are rising and new technologies are born. For example Google's free translation tool can be used by everyone but we have to keep in mind, the poor translations this service generates are the results of an old version (dated 1998) of the famous Systran software. Current Systran applications cost about 300$ depending on the language package. Translations generated by today’s Systran applications are well-known for being very close to original meanings and exemplary grammar. A lot of human translators feel in danger of losing their jobs. However, at the moment machine translation systems are not likely to replace humans but they are thought to speed up the human translator's work and to make the translation process more effective.
Difficulties for Machine Translation Systems
The difficulties and barriers in machine translation are not always comparable to human translators' difficulties. A lot of people wonder why computers are not able to generate perfect solutions although they are very fast in executing even complex calculations and have more knowledge available of nearly every topic in the world. But the sober reality is that a machine has approximately no text comprehension and often can not understand any context and relation between two sentences or words. That's why it cannot interpret or infer words or terms in some cases. In addition, although there are electronic information sources and more than one digital encyclopaedia the system is missing common knowledge and general education. The problems of machine translation can be separated into ambiguous terms, grammatical structures and syntactic relations.
Various Translation Systems
Operating Principle
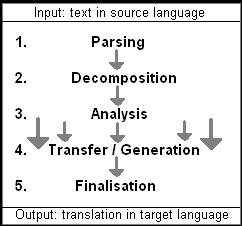
HOW MACHINES TRANSLATE
First, I want to point out how conventional machine translation systems work. The course of human translation which consists of reading and comprehending a text, transfering words and converting grammar structures, and finally, if necessary, improving the translation, is a great contrast to most translation softwares' operating principles which works like the following scheme, explanation and a simple example demonstrate:
1. Parsing
First of all parsing, a preparation which splits a text, leads the way. Documents are divided into sentences, sentences are partitioned into single words, terms or formatting information. Time or date information, names and terms of compound nouns, for example, must not be torn apart.
2. Morphological Decomposition
Bilingual dictionaries consist only of word stems and words' basic forms because it is impossible to save each form and modification of words in both the source and target language. To illustrate the problem, e.g. one German verb would require six entries in the dictionary only for its present indicative forms. So if each form were added, the size would explode. That's why an additional step to identify the basic forms and stems of the words – especially verbs and compound nouns – is necessary before the transfer can start. Often these algorithms are called "morphological decomposition".
3. Analysis
A translation's quality is determined by both syntactic and semantic analysis. Translation systems must be able to deal with sentential and grammatical structures, detect relations, references and general contexts to generate useful translations.
4. Transfer
After a text has been analysed, the systems try to find equivalents to the individual parts of a sentence by the aid of dictionary look-ups. The preparations from step one and two make these look-ups possible. The transfer is also influenced by step three because it considers the previous analysis' results. Some machine translation systems use so-called "intelligent dictionaries". These help to distinguish between the meanings of words which have more than one corresponding translation in the target language with regard on the subject of the whole text.
5. Finalisation
Finally the new sentences in the target language are changed with respect of structures and grammatical constructions. If it is necessary, the system changes the position of a word, for example.
Historical Background
Troyanskii suggested a concept of machine translator that was able to look up words in a bilingual dictionary. He also outlined the principles of an interlingual system. This system was expected to parse and analyse a text and to save it in a language, called interlingua, similar to the human language Esperanto. The next step was a synthesis, and afterwards the text was converted into the target language again. This had been Troyanskii's proposal for a solution before the computer was invented. Because his ideas were unreachable and unrealistic in those days, Troyanskii has been remaining unknown for the next 20 years, although even today his ideas are relevant for many translation systems which are based on the so-called interlingua method.
After World War II, America was prepared to support linguistic research. Some of the army's researchers, who had assisted in developing code-breaking systems to decrypt secret messages during the war, were cooperating with linguists and scientists like Warren Weaver. Such expert teams were able to accumulate knowledge of both languages and machines. The best known collection of information on this topic is the "Weaver Memorandum" (1949). This document can be seen as the starting point of machine translation research. The first success in translating showed the public demo of a machine translation. There, a machine was working on 52 Russian sentences using six grammar rules and a memory of about 250 words. The sentences were simple and short like “They prepared TNT.” Though, the Georgetown University students were proud of the output in 1954 and were able to convince a lot of companies to support and invest in machine translation research.